MongoDB图文详解
1.1 MongoDB概述
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB服务端可运行在Linux、Windows平台,支持32位和64位应用,默认端口为27017。
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
1.2 MongoDB 主要特点
1.2.1 文档
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
多个键及其关联的值有序地放在一起就构成了文档。MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。
{“greeting”:“hello,world”}这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。
例如:{“greeting”:“hello,world”,“foo”: 3} 文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。{“foo”: 3 ,“greeting”:“hello,world”}
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
使用文档的优点是:
- 文档(即对象)对应于许多编程语言中的本机数据类型
- 嵌入式文档和数组减少了对昂贵连接的需求
- 动态模式支持流畅的多态性
1.3.2 集合
集合就是一组文档,类似于关系数据库中的表。
集合是无模式的,集合中的文档可以是各式各样的。例如,{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。
但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。
例如,对于一个博客系统,可能包括blog.user 和blog.article 两个子集合,这样划分只是让组织结构更好一些,blog 集合和blog.user、blog.article 没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB 推荐的方法。
1.3.3 数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。
一个MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。
MongoDB 中存在以下系统数据库。
Admin数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin数据库中,那么该用户就自动继承了所有数据库的权限。Local数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。Config数据库:当MongoDB使用分片模式时,config数据库在内部使用,用于保存分片的信息。
1.3.4 数据模型
一个MongoDB 实例可以包含一组数据库,一个DataBase 可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。
一个Document包含一组field(字段),每一个字段都是一个key/value pair
key: 必须为字符串类型valuemongod --dbpath E:\MongoDB\data\db1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
:可以包含如下类型
- 基本类型,例如,`string,int,float,timestamp,binary` 等类型
- 一个`document`
- 数组类型
### 1.4 `Windows`安装`MongoDB`
#### 1.4.1 下载`MongoDB`
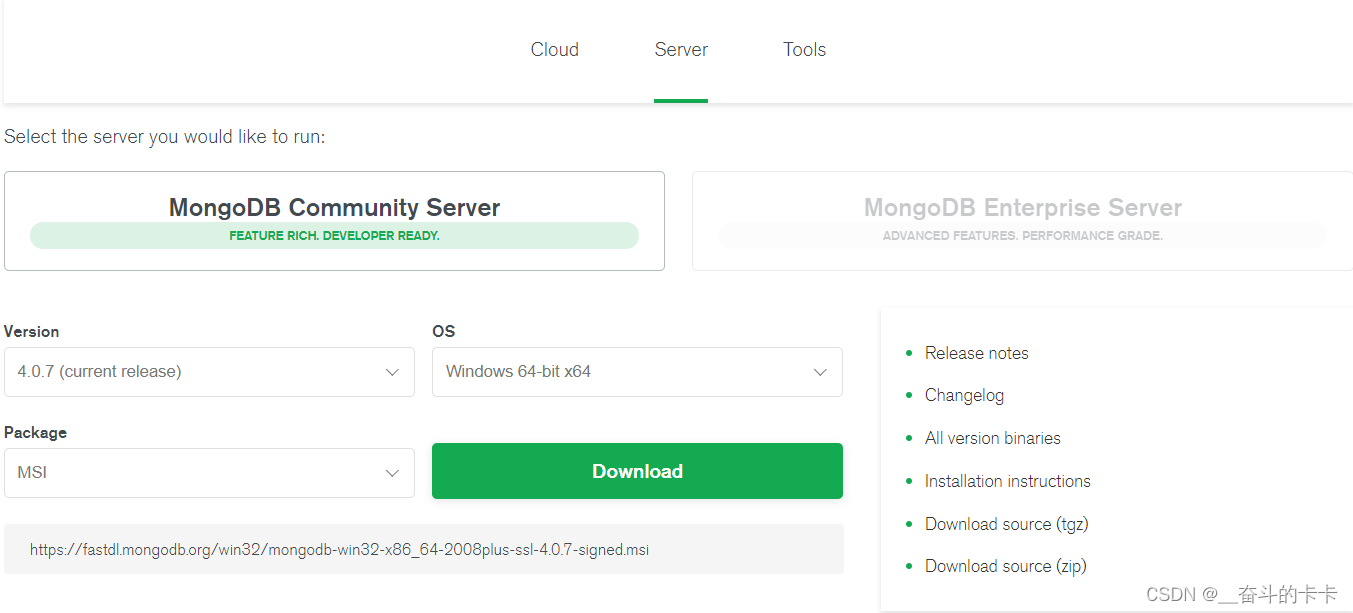
`MongoDB`提供了可用于`32`位系统和`64`位系统的预编译二进制包(新版本没有了`32`位系统的安装文件),你可以进入`MongoDB`官网下载安装,`MongoDB`的预编译二进制包的下载地址为:`https://www.mongodb.com/download-center/community`,打开之后会看到如下图,直接点击`Download`下载即可,也可以在`Version`中选择你想要的版本:
#### 1.4.2 安装`MongoDB`
双击打开文件进行安装,在安装过程中,可以通过点击 “`Custom`(自定义)” 按钮来设置你的安装目录。
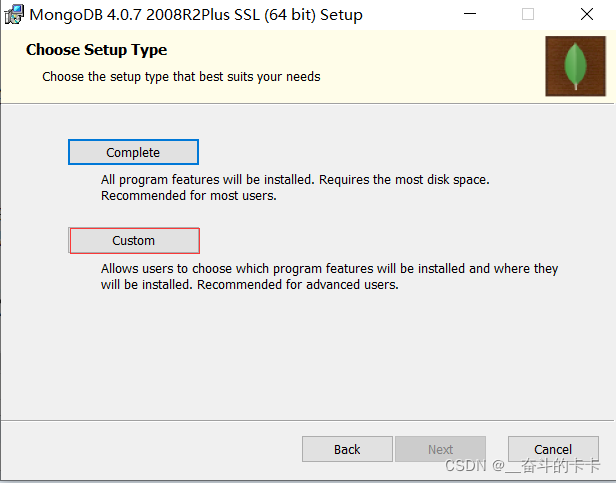
这里我选择安装在`E:\MongoDB`这个目录下(安装目录会影响我们后面的配置)
这里选择直接`next`
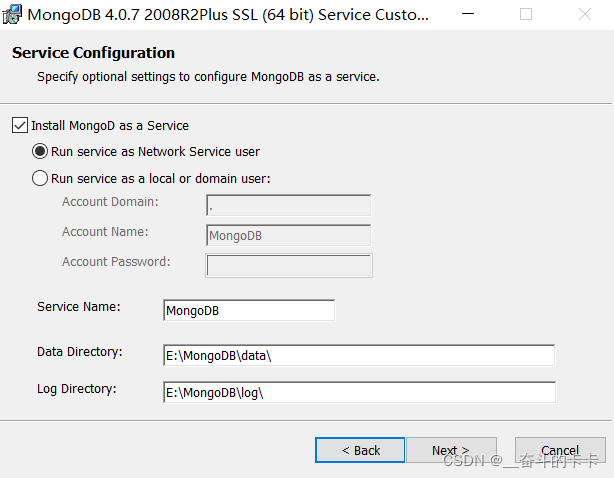
这里安装 `"Install MongoDB Compass" `不勾选,否则可能要很长时间都一直在执行安装,`MongoDB Compass`是一个图形界面管理工具,这里不安装也是没有问题的,可以自己去下载一个图形界面管理工具,比如`Robo3T`。
之后稍微等待一会就安装好了。
#### 1.4.3 配置`MongoDB`
`MongoDB`的安装过程是很简单的,但是配置就比较麻烦了,可能会遇到各种各样的问题,需要你有足够的耐心和仔细。
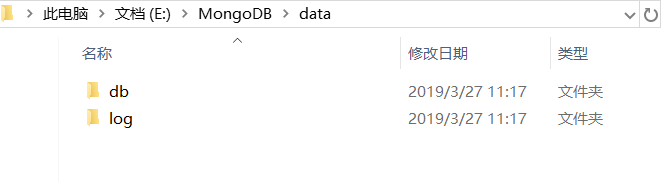
首先要在`MongoDB`的`data`文件夹里新建一个`db`文件夹和一个`log`文件夹:
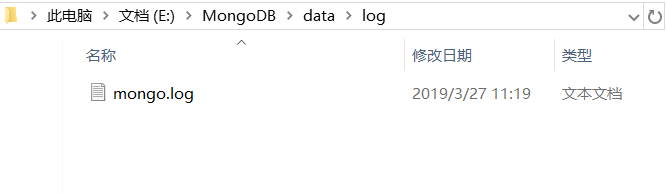
然后在log文件夹下新建一个mongo.log:
然后将`E:\MongoDB\bin`添加到环境变量`path`中,此时打开`cmd`窗口运行一下`mongo`命令,出现如下情况:

这是为什么呢?这是因为我们还没有启动`MongoDB`服务,自然也就连接不上服务了。那要怎么启动呢?在`cmd`窗口中运行如下命令:
1 | |
mongod –dbpath “E:\MongoDB\data\db” –logpath “E:\MongoDB\data\log\mongo.log” -install -serviceName “MongoDB”
1 | |
mongod –dbpath “E:\MongoDB\data\db” –logpath “E:\MongoDB\data\log\mongo.log” -install -serviceName “MongoDB”
1 | |
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.1.tgz
1 | |
tar -zxvf mongodb-linux-x86_64-rhel70-4.2.1.tgz
1 | |
mkdir -p /usr/local/mongo
mv mongodb-linux-x86_64-rhel70-4.2.1/* /usr/local/mongo/
1 | |
mkdir -p data/db #数据库目录
mkdir -p logs #日志目录
mkdir -p conf #配置文件目录
mkdir -p pids #进程描述文件目录
1 | |
vi /usr/local/mongo/conf/mongo.conf
1
#数据保存路径
dbpath=/usr/local/mongo/data/db/
#日志保存路径
logpath=/usr/local/mongo/logs/mongo.log
#进程描述文件
pidfilepath=/usr/local/mongo/pids/mongo.pid
#日志追加写入
logappend=true
bind_ip_all=true
#mongo默认端口
port=27017
#操作日志容量
oplogSize=10000
#开启子进程
fork=true
1 | |
/usr/local/mongo/bin/mongod -f /usr/local/mongo/conf/mongo.conf
1 | |
/usr/local/mongo/bin/mongo –host 127.0.0.1 –port 27017
1 | |
mongo
1 | |
show databases;
1 | |
use admin2
1 | |
show collections
1 | |
db.createCollection(‘集合名’)
1 | |
db.集合名.drop()
1 | |
db.集合名.insert(JSON数据)
1 | |
use test2 db.c1.insert({uname:”webopenfather”,age:18})
1 | |
会给每条数据增加一个全球唯一的
1 | |
键
_id键的组成
自己增加
1
_id可以,只需要给插入的
1
JSON数据增加
1
_id键即可覆盖(但实战强烈不推荐)
1
db.c1.insert({_id:1, uname:"webopenfather", age:18})
一次性插入多条数据
传递数据,数组中写一个个JSON数据即可
1 | |
快速插入10条数据
由于mongodb底层使用JS引擎实现的,所以支持部分js语法。因此:可以写for循环
1 | |
查询文档
1 | |
| 条件 | 写法 |
|---|---|
| 查询所有的数据 | {}或者不写 |
| 查询age=6的数据 | {age:6} |
| 既要age=6又要性别=男 | {age:6,sex:‘男’} |
| 查询的列(可选参数) | 写法 |
|---|---|
| 查询全部列(字段) | 不写 |
| 只显示age列(字段) | {age:1} |
| 除了age列(字段)都显示 | {age:0} |
其他语法
1 | |
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
| 实例练习 | |
| 查询所有数据 |
1 | |
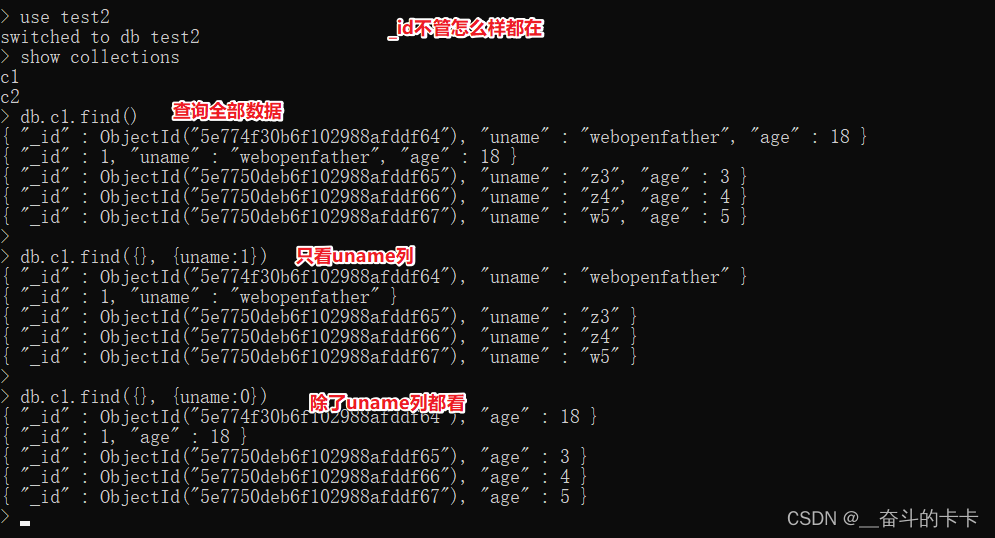
系统的_id无论如何都会存在
1、查询age大于5的数据
1 | |
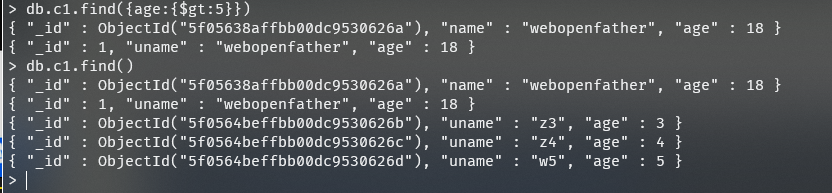
2、查询年龄是5岁、8岁、10岁的数据
1 | |
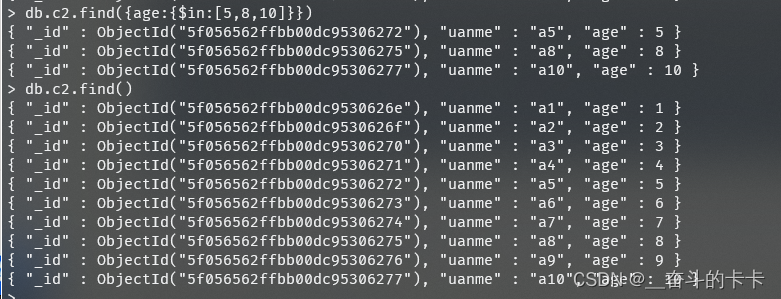
3、只看年龄列,或者年龄以外的列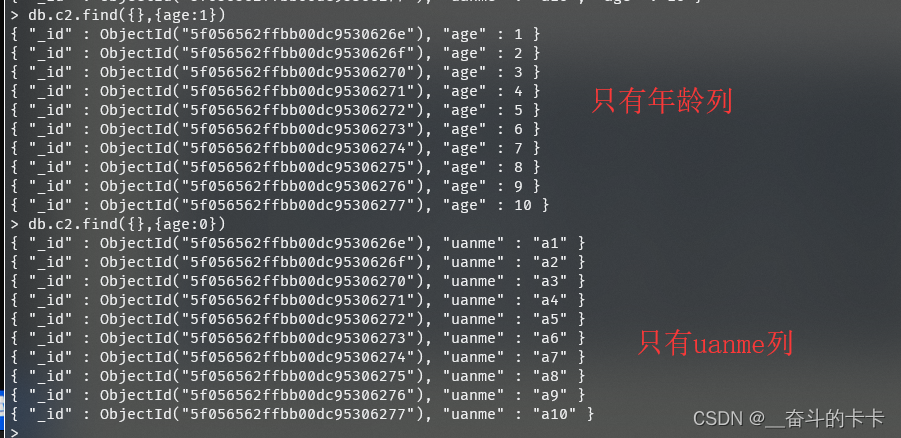
1.6.3 修改文档
1 | |
- 新数据此数据需要使用修改器,如果不使用,那么会将新数据替换原来的数据。
1db.集合名.update(条件,{修改器:{键:值}}[是否新增,是否修改多条,])
修改器作用inc递增rename重命名列set修改列值unset删除列 - 是否新增
指条件匹配不到数据则插入(true是插入,false否不插入默认)db.c3.update({uname:"zs30"},{$set:{age:30}},true)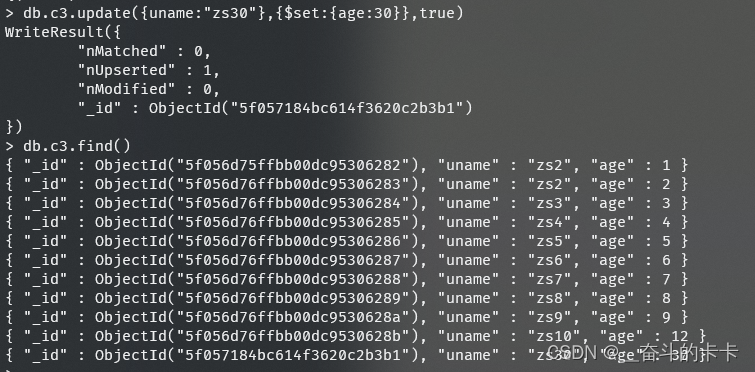
- 是否修改多条
指将匹配成功的数据都修改(true是,false否默认)db.c3.update({uname:"zs2"},{$set:{age:30}},false,true)
实例练习
准备工作
1 | |
1、将{uname:"zs1"}改为{uname:"zs2"}
1 | |
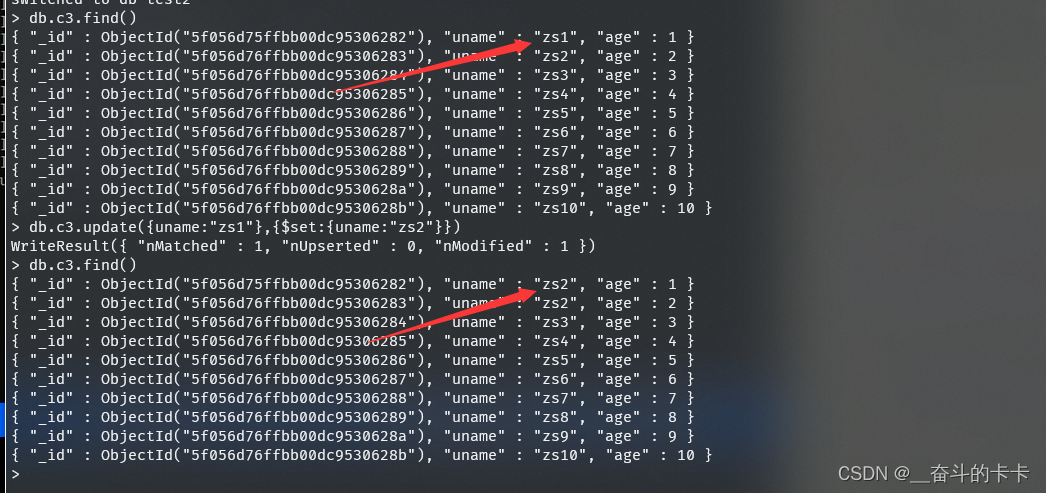
2、给{uname:"zs10"}的年龄加2岁或减2岁
1 | |
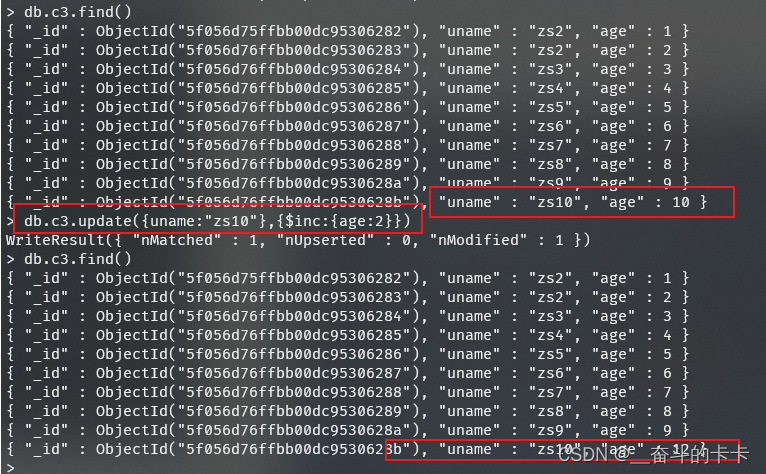
递减只需要将2改为-2即可。
综合练习插入数据:db.c4.insert( {uname:"神龙教主",age:888,who:"男",other:"非国人"});
1.6.4 删除文档
1 | |
- 是否删除一条
true:是(删除的数据为第一条)
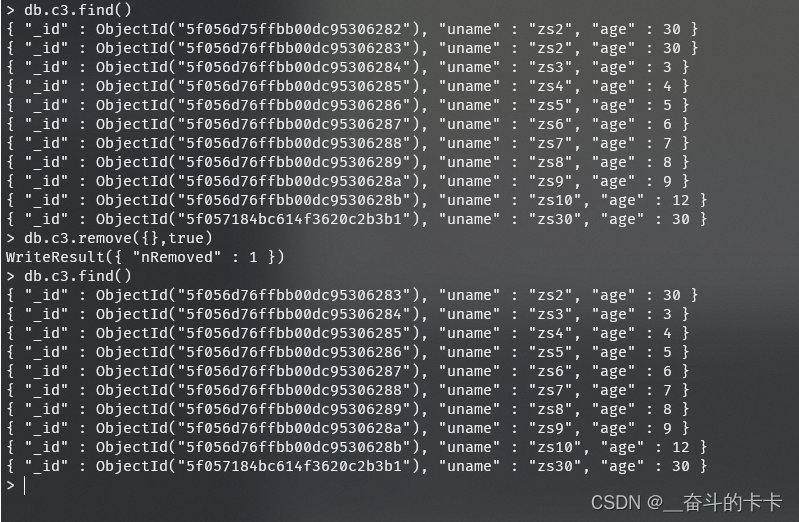
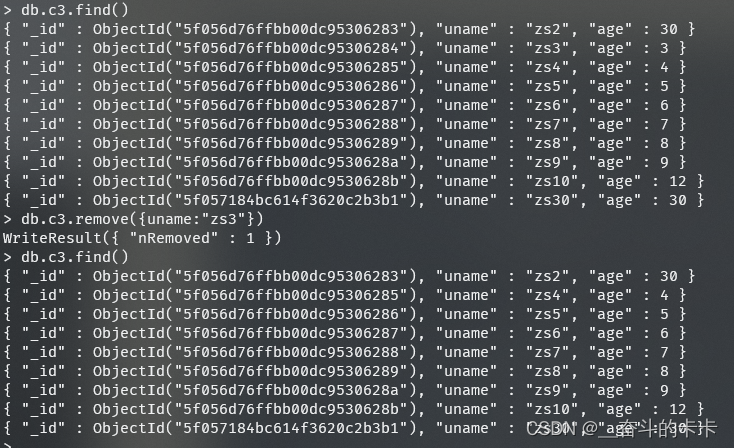
false:否
1 | |
1.6.5 总结
高级开发攻城狮统称:所有数据库都需要增删改查CURD标识
1 | |
增Create
1 | |
删Delete
1 | |
改Update
1 | |
查Read
1 | |
1.7 MongoDB存储数据类型
MongoDB中每条记录称作一个文档,这个文档和我们平时用的JSON有点像,但也不完全一样。JSON是一种轻量级的数据交换格式。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,JSON易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,但是JSON也有它的局限性,比如它只有null、布尔、数字、字符串、数组和对象这几种数据类型,没有日期类型,只有一种数字类型,无法区分浮点数和整数,也没法表示正则表达式或者函数。由于这些局限性,BSON闪亮登场啦,BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型,MongoDB使用BSON做为文档数据存储和网络传输格式。
1.7.1 数字
shell默认使用64位浮点型数值,如下:
1 | |
对于整型值,我们可以使用NumberInt或者NumberLong表示,如下:
1 | |
1.7.2 字符串
字符串也可以直接存储,如下:
1 | |
1.7.3 正则表达式
正则表达式主要用在查询里边,查询时我们可以使用正则表达式,语法和JavaScript中正则表达式的语法相同,比如查询所有key为x,value以hello开始的文档且不区分大小写:
1 | |
1.7.4 数组
数组一样也是被支持的,如下:
1 | |
数组中的数据类型可以是多种多样的。
1.7.5 日期
MongoDB支持Date类型的数据,可以直接new一个Date对象,如下:
1 | |
1.7.6 内嵌文档
一个文档也可以作为另一个文档的value,这个其实很好理解,如下:
1 | |
书有一个属性是作者,作者又有name,年龄等属性。
1.8 MongoDB 中的索引
1.8.1 索引创建
默认情况下,集合中的_id字段就是索引,我们可以通过getIndexes()方法来查看一个集合中的索引:
1 | |
结果如下:
1 | |
我们看到这里只有一个索引,就是_id。
现在我的集合中有10000个文档,我想要查询x为1的文档,我的查询操作如下:
1 | |
这种查询默认情况下会做全表扫描,我们可以用上篇文章介绍的explain()来查看一下查询计划,如下:
1 | |
结果如下:
1 | |
结果比较长,我摘取了关键的一部分。我们可以看到查询方式是全表扫描,一共扫描了10000个文档才查出来我要的结果。实际上我要的文档就排第二个,但是系统不知道这个集合中一共有多少个x为1的文档,所以会把全表扫描完,这种方式当然很低效,但是如果我加上 limit,如下:
1 | |
此时再看查询计划发现只扫描了两个文档就有结果了,但是如果我要查询x为9999的记录,那还是得把全表扫描一遍,此时,我们就可以给该字段建立索引,索引建立方式如下:
1 | |
1表示升序,-1表示降序。当我们给x字段建立索引之后,再根据x字段去查询,速度就非常快了,我们看下面这个查询操作的执行计划:
1 | |
这个查询计划过长我就不贴出来了,我们可以重点关注查询要耗费的时间大幅度下降。
此时调用getIndexes()方法可以看到我们刚刚创建的索引,如下:
1 | |
我们看到每个索引都有一个名字,默认的索引名字为字段名_排序值,当然我们也可以在创建索引时自定义索引名字,如下:
1 | |
此时创建好的索引如下:
1 | |
当然索引在创建的过程中还有许多其他可选参数,如下:
1 | |
关于这里的参数,我说一下:
1.
name表示索引的名称
2.dropDups表示创建唯一性索引时如果出现重复,则将重复的删除,只保留第一个
3.background是否在后台创建索引,在后台创建索引不影响数据库当前的操作,默认为false
4.unique是否创建唯一索引,默认false
5.sparse对文档中不存在的字段是否不起用索引,默认false
6.v表示索引的版本号,默认为2
7.weights表示索引的权重
此时创建好的索引如下:
1 | |
1.8.2 查看索引
getIndexes()可以用来查看索引,我们还可以通过totalIndexSize()来查看索引的大小,如下:
1 | |
1.8.3 删除索引
我们可以按名称删除索引,如下:
1 | |
表示删除一个名为xIndex的索引,当然我们也可以删除所有索引,如下:
1 | |
1.8.4 总结
索引是个好东西,可以有效的提高查询速度,但是索引会降低插入、更新和删除的速度,因为这些操作不仅要更新文档,还要更新索引,MongoDB 限制每个集合上最多有64个索引,我们在创建索引时要仔细斟酌索引的字段。
1.9 Java操作MongoDB
1.9.1 方式一
方式一采用的原生Java操作MongoDB
1.9.1.1 前期准备
首先我们需要驱动,MongoDB的Java驱动我们可以直接在Maven中央仓库去下载,也可以创建Maven工程添加如下依赖:
1 | |
建议通过Maven来添加依赖,如果自己下载jar,需要下载如下三个jar:
1 | |
另外,在使用Java操作 MongoDB 之前,记得启动 MongoDB
1.9.1.2 获取集合
所有准备工作完成之后,我们首先需要一个MongoClient,如下:
1 | |
然后通过如下方式获取一个数据库,如果要获取的数据库本身就存在,直接获取到,不存在MongoDB会自动创建:
1 | |
然后通过如下方式获取一个名为c1的集合,这个集合存在的话就直接获取到,不存在的话MongoDB会自动创建出来,如下:
1 | |
有了集合之后,我们就可以向集合中插入数据了。
1、增加操作
和在shell中的操作一样,我们可以一条一条的添加数据,也可以批量添加,添加单条数据操作如下:
1 | |
添加多条数据的操作如下:
1 | |
当然也可以通过 Robo 3T查看修改结果:db.集合名.find()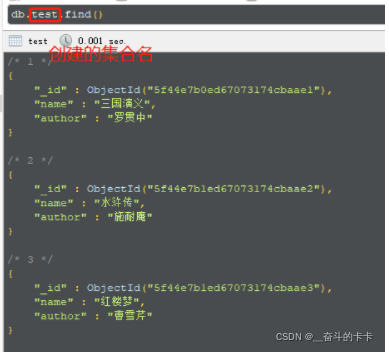
2、修改操作
可以修改查到的第一条数据,操作如下:
1 | |
上例中小伙伴们也看到了修改器要如何使用,不管是inc,用法都一致,我这里不再一个一个演示。也可以修改查到的所有数据,如下:
1 | |
3、删除操作
可以删除查到的一条数据,如下:
1 | |
也可以删除查到的所有数据:
1 | |
Filters里边还有其他的查询条件,都是见名知意,不赘述。
4、 查询操作
可以直接查询所有文档:
1 | |
也可以按照条件查询:
1 | |
其他的方法基本都是见名知意,这里不再赘述。
5、验证问题
上面我们演示的获取一个集合是不需要登录MongoDB数据库的,如果需要登录,我们获取集合的方式改为下面这种:
1 | |
MongoCredential是一个凭证,第一个参数为用户名,第二个参数是要在哪个数据库中验证,第三个参数是密码的char数组,然后将登录地址封装成一个ServerAddress,最后将两个参数都传入MongoClient中实现登录功能。
6、其他配置
在连接数据库的时候也可以设置连接超时等信息,在MongoClientOptions中设置即可,设置方式如下:
1 | |
1.9.2 方式二
主要讲解SpringBoot操作MongoDB实现增删改查的功能
1、pom.xml引入依赖
1 | |
2、创建application.yml
1 | |
3、创建实体类
创建包com.changan.mongodb,包下建包pojo 用于存放实体类,创建实体类
1 | |
4、创建数据访问接口com.changan.mongodb包下创建dao包,包下创建接口
1 | |
5、创建业务逻辑类com.changan.mongodb包下创建impl包,包下创建类
1 | |
6、创建测试类
1 | |
1.10 MongoDB之副本集配置
1.10.1 MongoDB主从复制
主从复制是MongoDB最早使用的复制方式, 该复制方式易于配置,并且可以支持任意数量的从节点服务器,与使用单节点模式相比有如下优点:
在从服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
可配置读写分离,主节点负责写操作,从节点负责读操作,将读写压力分开,提高系统的稳定性。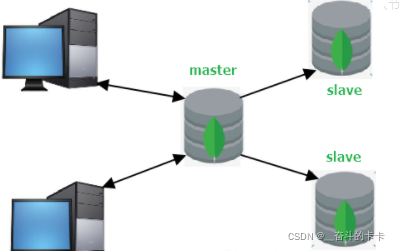
MongoDB 的主从复制至少需要两个服务器或者节点。其中一个是主节点,负责处理客户端请求,其它的都是从节点,负责同步主节点的数据。
主节点记录在其上执行的所有写操作,从节点定期轮询主节点获取这些操作,然后再对自己的数据副本执行这些操作。由于和主节点执行了相同的操作,从节点就能保持与主节点的数据同步。
主节点的操作记录称为oplog(operation log),它被存储在 MongoDB 的 local 数据库中。oplog 中的每个文档都代表主节点上执行的一个操作。需要重点强调的是oplog只记录改变数据库状态的操作。比如,查询操作就不会被存储在oplog中。这是因为oplog只是作为从节点与主节点保持数据同步的机制。
然而,主从复制并非生产环境下推荐的复制方式,主要原因如下两点:
1、灾备都是完全人工的 如果主节点发生故障失败,管理员必须关闭一个从服务器,然后作为主节点重新启动它。然后应用程序必须重新配置连接新的主节点。
2、数据恢复困难 因为oplog只在主节点存在,故障失败需要在新的服务器上创建新的oplog,这意味着任意存在的节点需要重新从新的主节点同步oplog。
因此,在新版本的MongoDB中已经不再支持使用主从复制这种复制方式了,取而代之的是使用副本集复制方式。
1.10.2 MongoDB副本集
MongoDB副本集(Replica Set)其实就是具有自动故障恢复功能的主从集群,和主从复制最大的区别就是在副本集中没有固定的“主节点;整个副本集会选出一个节点作为“主节点”,当其挂掉后,再在剩下的从节点中选举一个节点成为新的“主节点”,在副本集中总有一个主节点(primary)和一个或多个备份节点(secondary)。
除了primary和secondary之外,副本集中的节点还可以是以下角色:
| 成为primary | 对客户端可见 | 参与投票 | 延迟同步 | 复制数据 | |
|---|---|---|---|---|---|
| Default | √ | √ | √ | ∕ | √ |
| Secondary-Only | ∕ | √ | √ | ∕ | √ |
| Hidden | ∕ | ∕ | √ | ∕ | √ |
| Delayed∕ | √ | √ | √ | √ | |
| Arbiters | ∕ | ∕ | √ | ∕ | ∕ |
| Non-Voting | √ | √ | ∕ | ∕ | √ |
官方推荐的副本集最小配置需要有三个节点:一个主节点接收和处理所有的写操作,两个备份节点通过复制主节点的操作来对主节点的数据进行同步备份。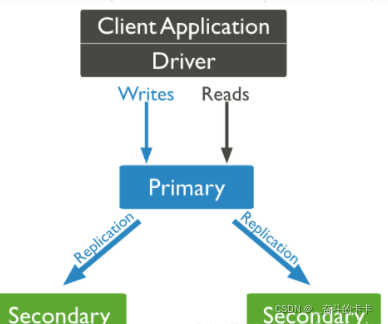
1.10.2.1 配置副本集
1、环境准备
副本集各节点IP如下:
172.16.250.234
172.16.250.239
172.16.250.240
首先,先对三个MongoDB 节点进行安装。
然后,依次修改各个节点的 mongodb.conf 配置文件,增加副本集相关配置,内容如下:
1 | |
配置完成之后,分别在三个节点上执行如下命令通过加载文件配置来启动MongoDB服务:
1 | |
至此,3个MongoDB实例都已经以副本集方式启动,但它们彼此之间现在还不会进行通信,仍需要进行一些配置。
2、副本集初始化
通过Shell连接到任意一个MongoDB实例,执行rs.initiate()方法对副本集进行初始化。
1 | |
如果在执行rs.initiate()方法时不传入任何参数,MongoDB 将以默认的配置文档对副本集进行初始化,后续可以再通过rs.add()方法来向副本集中添加成员。
3、副本集更新
1 | |
1 | |
例如,强制让一个节点成为Primary,可以将该节点的优先级设置成最高。
1 | |
4、副本集监控
1 | |
1.10.2.2 副本集测试
在Primary 上插入一万条客户数据:
1 | |
在Secondary上查看客户数据是否已经同步:
1 | |
故障转移测试
执行如下命令关闭Primary节点,查看其他2个节点的情况:
1 | |
再次启动172.16.250.239:27017节点,由于其选举优先级最高,自动被选举为Primary。
1 | |
1.10.2.3 开启安全认证
创建用户
登录 PRIMARY节点创建用户,在此我们对 test 库开启安全认证。
1 | |
创建keyFile文件
先停掉所有SECONDARY节点的MongoDB服务,然后再停掉PRIMARY节点的MongoDB服务,并在PRIMARY节点所在服务器上创建keyFile文件。
1 | |
将生成的keyFile文件拷贝到其他节点服务器上,并修改文件的操作权限为 600。
1 | |
更新启动配置文件
修改PRIMARY节点的 mongodb.conf 文件,增加如下内容:
1 | |
修改SECONDARY节点的 mongodb.conf 文件,增加如下内容:
1 | |
启动副本集
先以 --auth 方式启动PRIMARY节点:
1 | |
再启动SECONDARY节点:
1 | |
登录测试
1 | |
admin用户只能看到test库。